Joseph (AJ) Horch

As a Data Scientist with a Master’s degree in Data Science and significant experience in financial journalism, I leverage AI, cutting-edge technologies, and predictive analytics to develop innovative solutions that uncover actionable insights. My background enables effective problem-solving, adaptability and communication, which are essential for making data-driven decisions in diverse sectors.
View My LinkedIn Profile
Selected projects in data science, machine learning, and NLP
Automating Interview Questions
I completed my MSc in Data Science in June of 2024. While in school, I developed new skills in statistical analysis and machine learning techniques. I am currently looking for a permanent position within a data science team. I’ve been fortunate to land a few interviews here and there. However, since being out of school, I’ve noticed my grasp of concepts slip. I haven’t performed as well during technical interviews as I would have wanted to. To address this, I wanted an easy way to test my knowledge of statistics, probability, ML fundamentals, and SQL. Using this excellent TDS article by Terence Shin, I created a project that would email me questions every day so I could test myself and identify gaps in my knowledge.
I used Selenium and BeautifulSoup to scrape the TDS article, stored the questions and answers in a DataFrame, and then utilised the Windows Task Scheduler to set up a daily email.
Spotify playlist recommendation models:
Scraped personal and public Spotify playlists to assess 8 machine learning supervised algorithms. These algorithms were used to create new playlists. The features were scaled when necessary, and hyperparameters were tuned to get the best results.
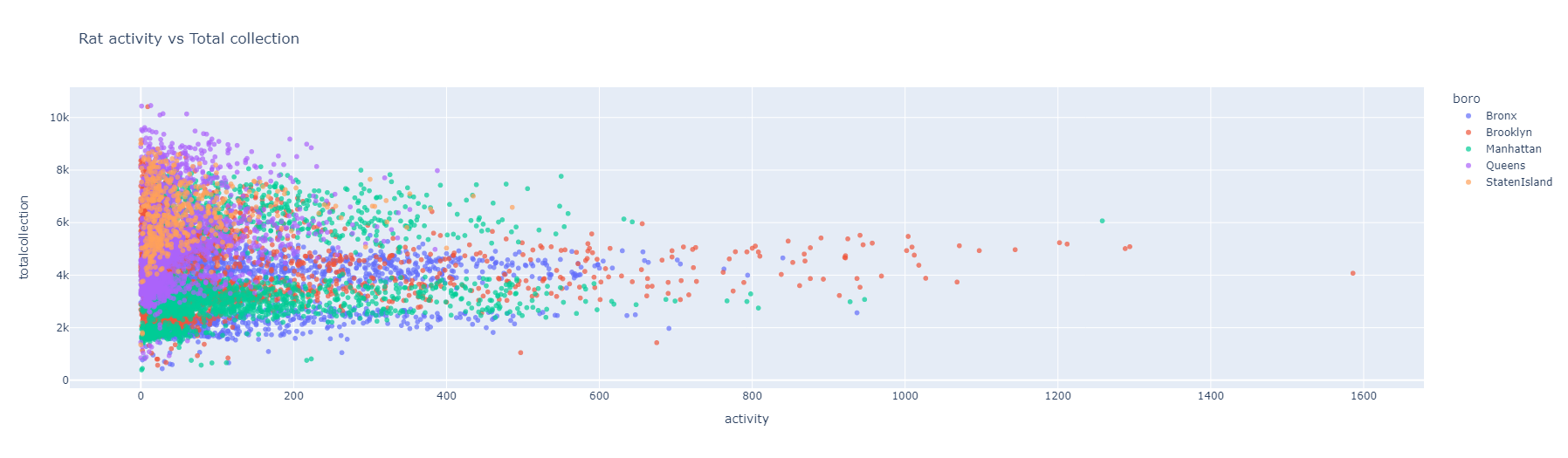
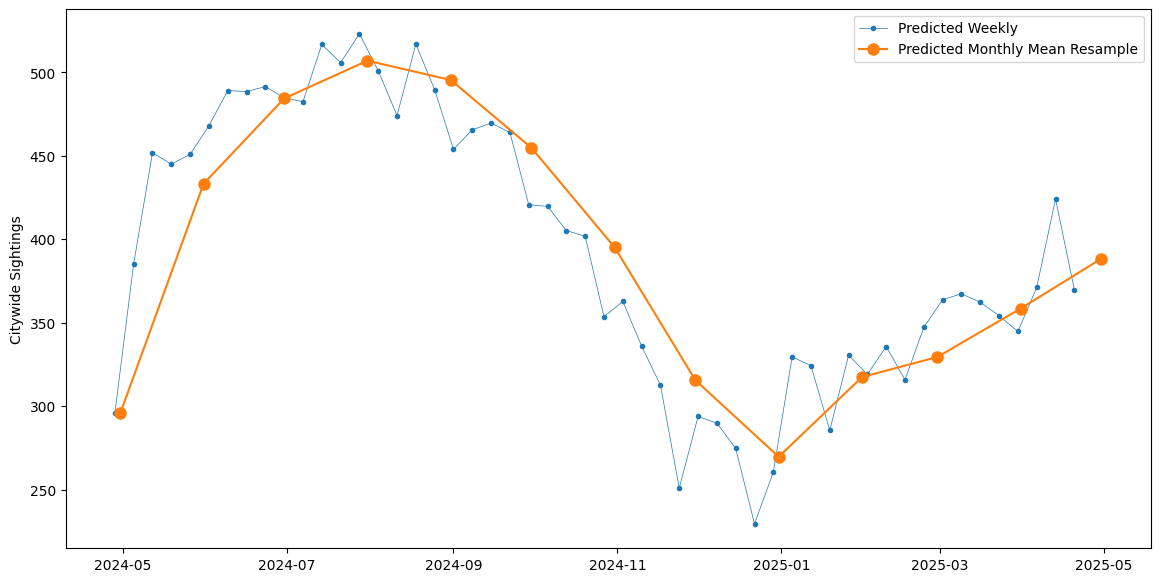
Forecasting NYC rat sightings
Employed SARIMA to forecast rat sightings across NYC neighbourhoods. Identified what neighbourhoods should expect more sightings, resulting in actionable public policy considerations to reduce sightings.
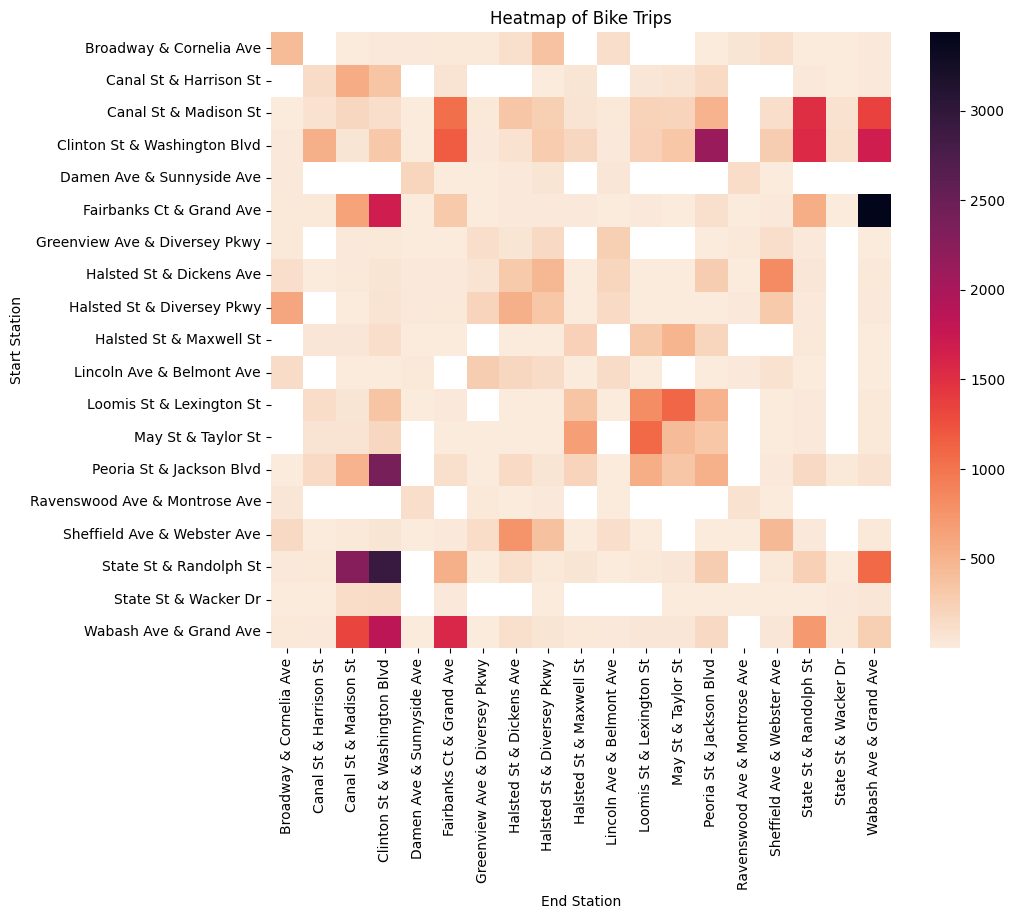
Spatial temporal analysis of bike sharing
Spatial temporal visualizations were analyzed to discover how commuters use Chicago’s public bike-sharing scheme. Actionable insights include sites for new bike stations and bike redistribution.
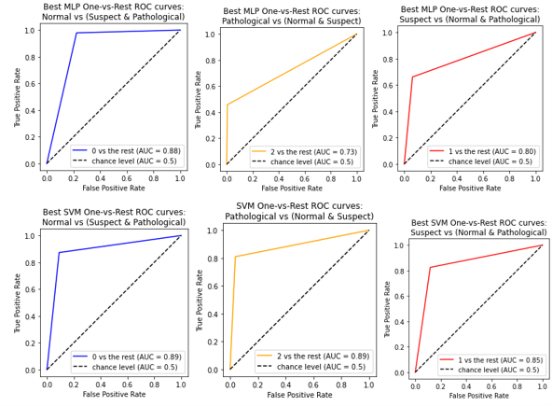
MLP & SVM optimization for Classification
This project intends to present a critical and even-handed evaluation of two algorithms’ performance in a supervised classification task on Cardiotocography records from fetuses. The two algorithms compared are Multilayer Perceptron (MLP) and Support Machine Vector(SVM). Multiply experiments were conducted on each model, with differing hyperparameters in a grid search. The test of the top models were evaluated and compared using confusion matrices and Receiver Operation Curves. This project required using PyTorch and Sci-Key Learn.
SQL for data job market
Focusing on data analyst and scientist roles, this project explores top-paying jobs, in-demand skills and where high demand meets high salary in data analytics.
These are the questions I answered
- What are the top-paying data analyst jobs?
- Where are jobs being posted in the UK
- What skills are required for these top-paying jobs?
- What skills are most in-demand for data analysts?
- Which skills are associated with higher salaries?
- What are the most optimal skills to learn
In progress
- Personal Finance Large Language Model
- Twitter Sentiment analysis
- Flight delay predictor
- European football analysis SQL